AudioGuard : controlling microphone access on per-process basis
Intro
Long-term surveillance hinges (among other things) on microphone capture and recording capabilities, serving as a cornerstone of persistent monitoring operations. Threat actors can silently harvest sensitive intelligence from team meetings, voice chats, and internal discussions - providing access to organizational insights. In this blogpost, our goal is to uncover the internals behind the audio subsystem on Windows, and design a protection solution with the capability of controlling microphone access on a per-process basis. All sources can be found here
Some KS terminology
Whenever we open our webcam, activate our microphone or enable sound, the system needs to read or write related data such as your voice or captured images into RAM. Kernel Streaming (KS) refers to the Microsoft-provided services that support kernel-mode processing of streamed data. KS serves as a standardized interface for multimedia devices, and aims to provide low latency and simplified multimedia driver development. Microsoft provides three multimedia class driver models: port class, stream class, and AVStream. These class drivers are implemented as export drivers (kernel-mode DLLs) in the system files portcls.sys, stream.sys, and ks.sys. the portcls.sys driver is what most hardware drivers for PCI and DMA-based audio devices are based on. the port clsss driver supplies a set of port drivers that implement most of the generic kernel streaming (KS) filter functionality, it’s essentially another abstraction on top of ks.sys making the job of driver devs easier.
KS pins and filters
Conceptually, a stream undergoes processing as it flows along a data path containing some number of processing nodes. A set of related nodes is grouped together to form a KS filter, which represents a more-or-less independent block of stream-processing functionality. More complex functions can be constructed in a modular way by cascading several filters together to form a filter graph. A KS filter is implemented as a kernel-mode KS object that encapsulates a number of related stream-processing callbacks, described by a KSFILTER_DESCRIPTOR structure. KS filters are connected together through their pins. A pin on an audio filter can be thought of as an audio jack. A client instantiates an input or output pin on a filter when the client needs to route a data stream into or out of that filter. Similarly to a KSFILTER, a KSPIN is described by a KSPIN_DESCRIPTOR. For example, a filter that performs audio mixing might have one pin factory that can instantiate a single output pin and a second pin factory that can instantiate several input pins.
The windows audio subsystem
The audio architecture changed dramatically in the rewrite that was done in Vista. Technically, audio drivers do communicate through kernel streaming, but the graph typically contains only one filter. The graph is owned and operated by the Audio Engine process (Audiodg.exe) Client applications eventually get down to WASAPI calls, which result in requests being sent to the Audio Engine through several layers of IPC. The Audio Engine then manages the communication with the device, not through IOCTL_KS_READ_STREAM (which is used for camera devices) but rather through a shared circular buffer, the Audio Engine writes and reads from this buffer without kernel involvement. This is why audio effects are now done by APOs (audio processing objects), which are COM DLLs that load in the Audio Engine process. Having said that, certian KS IOCTLs are still in use, and we will discuss them in detail later on in the blogpost.
UM Components - AudioSes.dll
As mentioned client applications eventually get down to WASAPI calls, namely through the use of the IAudioClient COM interface. AudioSes.dll is the in-process COM server that implements IAudioClient.
UM Components - AudioEng.dll
The audio engine (AudioEng.dll) is loaded by the Audio Device Graph process (Audiodg.exe), and is responsible for:
- Mixing and processing of audio streams
- Owning the filter graph and loading APOs (Audio Processing Objects)
In addition, it handles the communication with the kernel-mode counterpart of the audio subsystem, through the AudioKSE.dll module. It’s worth mentioning the Audio Device Graph was once a protected process, but at least from Windows 10 that is no more the case.
UM Components - AudioSrv.dll
The audio service (AudioSrv.dll) loads in an instance of svchost, and is responsible for:
- Starting and controlling audio streams
- Implementing Windows policies for background audio playback, ducking, etc.
The audio service sits between AudioEng.dll and AudioSes.dll (client applications), and communicates with clients using LRPC over the following ALPC port.

The kernel side of the audio subsystem
To better understand the kernel interaction within the audio subsystem, I wrote a generic plug & play upper filter that logs IRPs, and installed it for the media device class:

Despite it’s misleading description, joysticks go into Human Interface Devices, and video capture devices typically go into Cameras.
Typically, the audio stack will be constructed from devices managed by ksthunk.sys, HdAudio.sys and HdAudBus.sys:

Upon restarting the system and running a sample audio recording application, we can examine our driver’s output.
There are hundereds of IOCTLs in play, most of them related to audio format negotiation
Nevertheless, after some reserach - these are the requests I found to be worth mentioning
IRP_MJ_CREATE -> ...\.e.m.i.c.i.n.w.a.v.e.
* Corresponding to a KsOpenDefaultDevice call
IOCTL_KS_PROPERTY -> KSPROPERTY_PIN
IRP_MJ_CREATE -> <KSNAME_Pin><KSPIN_CONNECT><KSDATAFORMAT>
IOCTL_KS_PROPERTY -> KSPROPERTY_CONNECTION_STATE -> KSSTATE_ACQUIRE (Set)
IOCTL_KS_PROPERTY -> KSPROPERTY_CONNECTION_STATE -> KSSTATE_PAUSE (Set)
IOCTL_KS_PROPERTY -> KSPROPERTY_CONNECTION_STATE -> KSSTATE_RUN (Set)
***
Recording Starts
***
...
***
Recording Ends
***
IOCTL_KS_PROPERTY -> KSPROPERTY_CONNECTION_STATE -> KSSTATE_ACQUIRE (Set)
IOCTL_KS_PROPERTY -> KSPROPERTY_CONNECTION_STATE -> KSSTATE_STOP (Set)
As expected, those IRPs are being generated from the audio engine (through AudioKSE.dll) in the audiodg process.
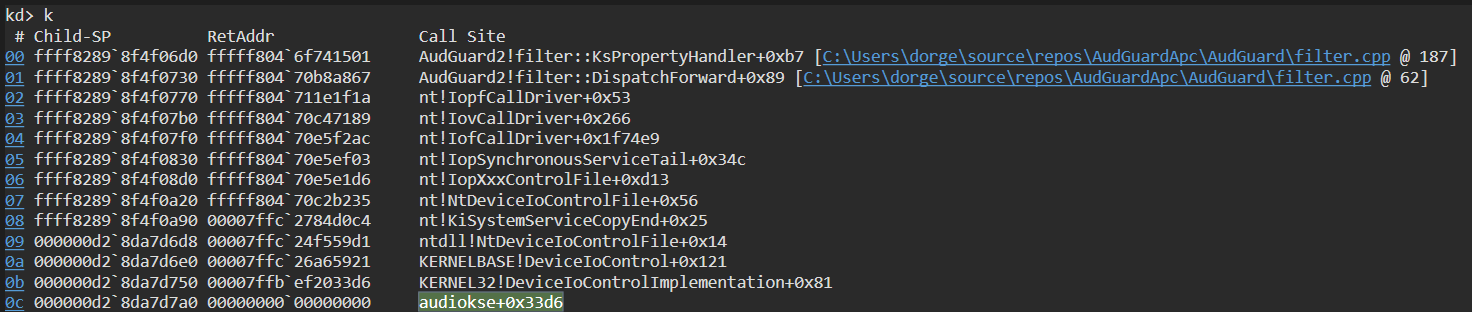
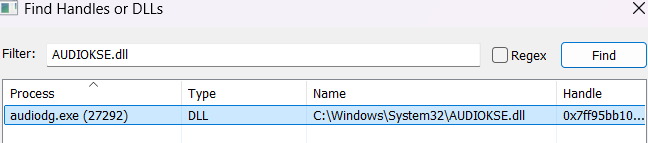
IRP_MJ_CREATE for KSPIN
Upon obtaining a handle to a KSFILTER object (e.g. via a KsOpenDefualtDevice call), the audio engine initiates another create operation targeted at one of the filter’s pins. Bizarrely, as disovered by Michael Maltsev in his camera stack focused research, the file name in the IRP_MJ_CREATE operation for the pin begins with the KSNAME_Pin GUID and is followed by a KSPIN_CONNECT structure that contains the pin id, and a binary KSDATAFORMAT structure that defines the format to be used. More about the avaliable audio formats here.
IOCTL_KS_PROPERTY
IOCTL_KS_PROPERTY is used to get or set properties, or to determine the properties supported by a KS object. The format of an IOCTL_KS_PROPERTY request conssists of a property descriptor, passed in the input buffer, and a property value - passed over the output buffer. The type of the descriptor is mostly:
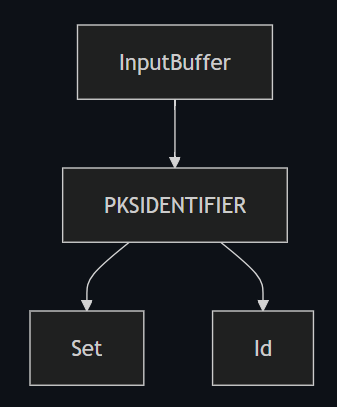
PKSIDENTIFIER->Setpoints to a property setPKSIDENTIFIER->Idpoints to the specific property within the specefied property set
Of course, the type of the property value varies and depends on the property.
the property descriptor and value types are often documented via a usage summary table in the MSDN page for the property.
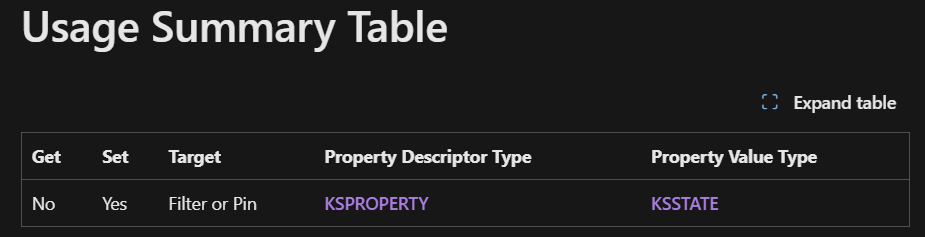
KSPROPERTY and KSIDENTIFIER are aliases, and have the same definition.
As indicated by our driver’s log, the property KSSTATE_RUN of the KSPROPERTY_CONNECTION_STATE property set is set to start a recording. On the other hand, to stop the recording one would have to set KSSTATE_STOP.
As with all KS IOCTLs, IOCTL_KS_PROPERTY is defined as METHOD_NEITHER, meaning data is passed via raw user addresses accessible only in the caller’s context.
Blocking microphone access
AVs allow the user to conifgure the type of protection applied on the microphone, typically this setting exists under the privacy protection options.
Let’s start by implementing the most robust configuration - blocking any attempt to record our microphone.
One approach is to block incoming IOCTL_KS_PROPERTY IRPs setting the KSSTATE_RUN property of the KSPROPERTY_CONNECTION_STATE property set. However, to be able to support other configuration options in the future, a more generic design would be to notify a UM service whenever such request occurs, using the inverted call model. Next, we can place the IRP in a cancel safe queue, wait for a response from the service indicating the way the driver should handle the request, extract it from the queue and complete it accordingly. Code to handle an IOCTL_KS_PROPERTY in the said design would look like the following:
bool filter::KsPropertyHandler(PDEVICE_OBJECT DeviceObject, PIRP Irp, PIO_STACK_LOCATION IoStackLocation)
{
GUID PropertysetConnection = GUID_PROPSETID_Connection;
ULONG OutputBufferLength = IoStackLocation->Parameters.DeviceIoControl.OutputBufferLength;
ULONG InputBufferLength = IoStackLocation->Parameters.DeviceIoControl.InputBufferLength;
if (!InputBufferLength || !OutputBufferLength)
return AUDGUARD_COMPLETE;
PVOID InputBuffer = IoStackLocation->Parameters.DeviceIoControl.Type3InputBuffer;
PVOID OutputBuffer = Irp->UserBuffer;
// IOCTL_KS_PROPERTY is method neither, we are provided with the user addresses as is
// since AudioGuard is attached at the top of the stack we can access these buffers directly
// must be done in a try except as the buffer might get freed any time by the user thread
__try
{
ProbeForRead(InputBuffer, InputBufferLength, sizeof(UCHAR));
PKSIDENTIFIER KsIdentifier = reinterpret_cast<PKSIDENTIFIER>(InputBuffer);
if (IsEqualGUID(KsIdentifier->Set, PropertysetConnection))
{
if (KsIdentifier->Id == KSPROPERTY_CONNECTION_STATE && KsIdentifier->Flags == KSPROPERTY_TYPE_SET)
{
KSSTATE KsStatePtr = *reinterpret_cast<PKSSTATE>(OutputBuffer);
switch (KsStatePtr)
{
case KSSTATE_STOP:
DbgPrint("[*] AudioGuard :: request to set KSSTATE_STOP\n");
break;
case KSSTATE_ACQUIRE:
DbgPrint("[*] AudioGuard :: request to set KSSTATE_ACQUIRE\n");
break;
case KSSTATE_PAUSE:
DbgPrint("[*] AudioGuard :: request to set KSSTATE_PAUSE\n");
break;
// sent on capture start!
// handle it by placing the IRP in an IRP queue and prompt the user asynchronously
// since we are not going to touch the buffers anymore we don't have to map them
// in case the user allows processing to proceed we will call IofCallDriver in an apc, allowing ksthunk to map these user addresses
case KSSTATE_RUN:
DbgPrint("[*] AudioGuard :: request to set KSSTATE_RUN\n");
// notify service of KS request
pCsqIrpQueue ClientIrpQueue = reinterpret_cast<pCsqIrpQueue>(globals::ClientDeviceObject->DeviceExtension);
PIRP ClientIrp = IoCsqRemoveNextIrp(&ClientIrpQueue->CsqObject, nullptr);
if (!ClientIrp)
{
return AUDGUARD_COMPLETE;
}
Irp->Tail.Overlay.DriverContext[0] = DeviceObject;
// IOCsqInsertIrp marks the IRP as pending
IoCsqInsertIrp(&globals::g_pKsPropertyQueue->CsqObject, Irp, nullptr);
ClientIrp->IoStatus.Status = STATUS_SUCCESS;
ClientIrp->IoStatus.Information = 0;
IoCompleteRequest(ClientIrp, IO_NO_INCREMENT);
return AUDGUARD_PEND;
}
}
}
}
__except (EXCEPTION_EXECUTE_HANDLER)
{
DbgPrint("[*] AudioGuard :: exception accessing buffer in ksproperty handler\n");
}
return AUDGUARD_COMPLETE;
}
And to handle the response from the service:
NTSTATUS client::device_control(PDEVICE_OBJECT DeviceObject, PIRP Irp)
{
...
case IOCTL_AUDGUARD_USER_DIALOG:
KsIrp = IoCsqRemoveNextIrp(&globals::g_pKsPropertyQueue->CsqObject, nullptr);
if (!KsIrp)
break;
ProtectionServiceConfig = *reinterpret_cast<int*>(Irp->AssociatedIrp.SystemBuffer);
// complete the previously pended IOCTL_KS_PROPERTY
// we have to do it from the caller's context since ksthunk (below us) will try to map user addresses
if (apc::queue_completion_kernel_apc(KsIrp, ProtectionServiceConfig))
status = STATUS_SUCCESS;
...
}
Completion thread context
KS IOCTLs are METHOD_NEITHER, remember? Once we decide to pend a KS IOCTL, we have to ensure we don’t complete it in an arbitrary thread context, as ksthunk, the driver below us in the stack, will try to map and access the provided user buffers which are valid only in the caller’s context. That means when completing the previously pended IRP, we must do that through queueing an apc to the
caller thread.
void apc::normal_routine(PVOID NormalContext, PVOID SystemArgument1, PVOID SystemArgument2)
{
UNREFERENCED_PARAMETER(SystemArgument1);
UNREFERENCED_PARAMETER(SystemArgument2);
pApcContext ApcContx = reinterpret_cast<pApcContext>(NormalContext);
PDEVICE_OBJECT FilterDeviceObject = reinterpret_cast<PDEVICE_OBJECT>(ApcContx->Irp->Tail.Overlay.DriverContext[0]);
filter::pDeviceExtension DevExt = reinterpret_cast<filter::pDeviceExtension>(FilterDeviceObject->DeviceExtension);
int ProtectionServiceConfig = ApcContx->ProtectionServiceConfig;
// if service is configured to block all access complete with status denied
if (ProtectionServiceConfig == AUDGUARD_BLOCK_MIC_ACCESS)
{
DbgPrint("[*] AudioGuard :: completing IOCTL_KS_PROPERTY IRP with access denied!\n");
ApcContx->Irp->IoStatus.Status = STATUS_ACCESS_DENIED;
ApcContx->Irp->IoStatus.Information = 0;
IofCompleteRequest(ApcContx->Irp, IO_NO_INCREMENT);
}
// otherwise pass the request down
else
{
DbgPrint("[*] AudioGuard :: passing IOCTL_KS_PROPERTY IRP down the audio stack!\n");
IoSkipCurrentIrpStackLocation(ApcContx->Irp);
IofCallDriver(DevExt->LowerDeviceObject, ApcContx->Irp);
}
IoReleaseRemoveLock(&DevExt->RemoveLock, ApcContx->Irp);
ExFreePoolWithTag(ApcContx, TAG);
}
More work to be done
Our goal is to design a solution capable of blocking microphone access based on the process trying to access it. The IOCTL_KS_PROPERTY - KSSTATE_RUN IRP is sent from the audio engine, so all requests seem as if they were originated from it. We need to find a way to connect context back to the recording process, so let’s take a closer look at what we have so far with our driver involved:
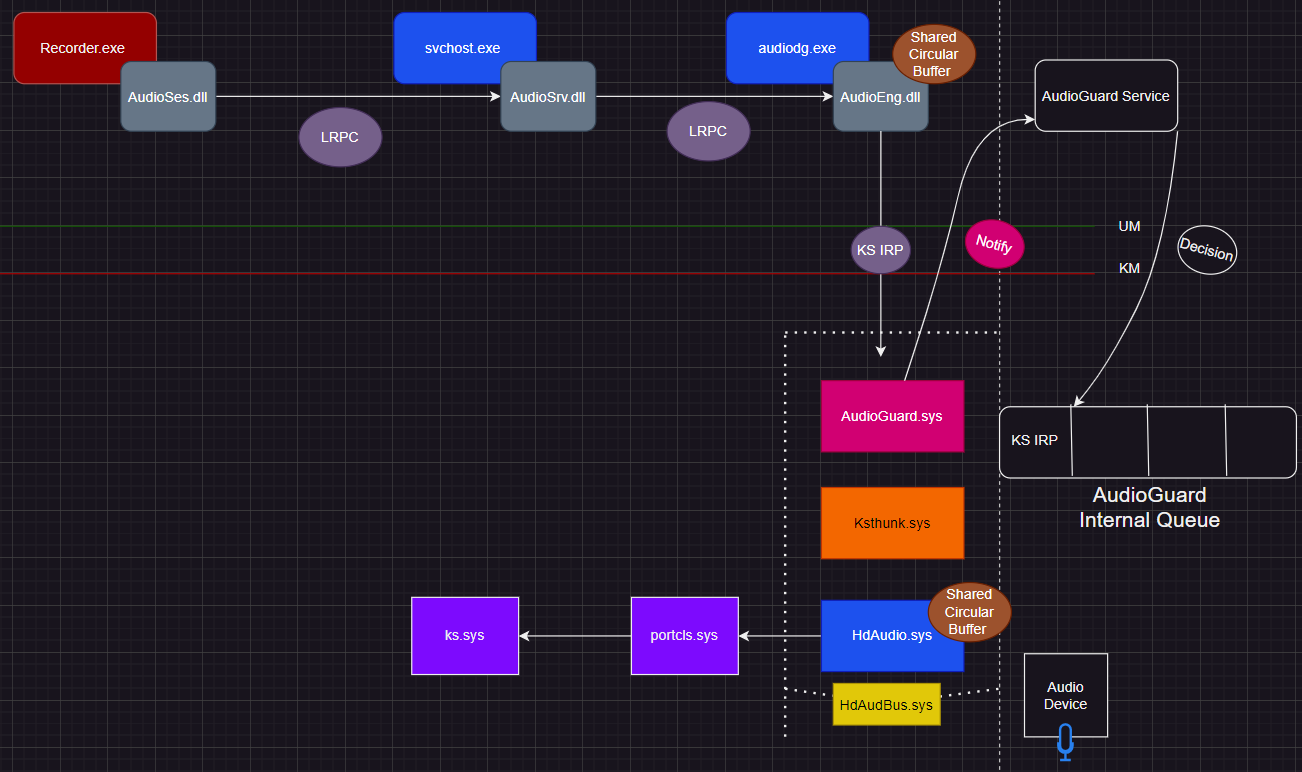
In the next sections, we will explore some of the internals behind the flow of capturing microphone input in more detail, aiming to find a reliable way to trace back to the recording process.
The IAudioClient COM interface
The following is sample code for using the IAudioClient interface (exported by WASAPI) to record input from a connected microphone and save it to a .wav file:
hr = CoInitializeEx(NULL, COINIT_SPEED_OVER_MEMORY);
EXIT_ON_ERROR(hr)
hr = CoCreateInstance(
__uuidof(MMDeviceEnumerator), NULL,
CLSCTX_ALL, __uuidof(IMMDeviceEnumerator),
(void**)&pEnumerator);
EXIT_ON_ERROR(hr)
hr = pEnumerator->GetDefaultAudioEndpoint(
eCapture, eConsole, &pDevice);
EXIT_ON_ERROR(hr)
hr = pDevice->Activate(
__uuidof(IAudioClient), CLSCTX_ALL,
NULL, (void**)&pAudioClient);
EXIT_ON_ERROR(hr)
hr = pAudioClient->GetMixFormat(&pwfx);
EXIT_ON_ERROR(hr)
// Adjust wave header with audio format
waveHeader.numChannels = pwfx->nChannels;
waveHeader.sampleRate = pwfx->nSamplesPerSec;
waveHeader.byteRate = pwfx->nAvgBytesPerSec;
waveHeader.blockAlign = pwfx->nBlockAlign;
waveHeader.bitsPerSample = pwfx->wBitsPerSample;
hr = pAudioClient->Initialize(
AUDCLNT_SHAREMODE_SHARED,
0,
hnsRequestedDuration,
0,
pwfx,
NULL);
EXIT_ON_ERROR(hr)
hr = pAudioClient->GetBufferSize(&bufferFrameCount);
EXIT_ON_ERROR(hr)
hr = pAudioClient->GetService(
__uuidof(IAudioCaptureClient),
(void**)&pCaptureClient);
EXIT_ON_ERROR(hr)
// Start capturing
hr = pAudioClient->Start();
EXIT_ON_ERROR(hr)
// Write wave header to output file
outFile.write(reinterpret_cast<char*>(&waveHeader), sizeof(waveHeader));
// Record for 1 minute
for (int i = 0; i < 60; i++) {
Sleep(1000); // Wait for 1 second
hr = pCaptureClient->GetNextPacketSize(&packetLength);
EXIT_ON_ERROR(hr)
while (packetLength != 0) {
hr = pCaptureClient->GetBuffer(
&pData,
&numFramesAvailable,
&flags, NULL, NULL);
EXIT_ON_ERROR(hr)
if (flags & AUDCLNT_BUFFERFLAGS_SILENT) {
pData = NULL; // Tell CopyData to write silence.
}
// Only write if pData is not NULL
if (pData != NULL) {
outFile.write(reinterpret_cast<char*>(pData),
numFramesAvailable * pwfx->nBlockAlign);
waveHeader.dataSize += numFramesAvailable * pwfx->nBlockAlign;
}
hr = pCaptureClient->ReleaseBuffer(numFramesAvailable);
EXIT_ON_ERROR(hr)
hr = pCaptureClient->GetNextPacketSize(&packetLength);
EXIT_ON_ERROR(hr)
}
}
// Stop capturing
hr = pAudioClient->Stop();
EXIT_ON_ERROR(hr)
Exit:
// Update chunk size in wave header
waveHeader.chunkSize = waveHeader.dataSize + 36;
// Rewrite wave header to output file with updated chunk and data size
outFile.seekp(0, std::ios::beg);
outFile.write(reinterpret_cast<char*>(&waveHeader), sizeof(waveHeader));
there are other APIs that expose similar functionality, under the hood they operate in a similar manner, the differences are negligible
Reversing audiosrv!AudioServerStartStream
The method of interest is pAudioClient->Start(), which as the name suggests - starts the audio recording by streaming data between the endpoint buffer and the audio engine. under the hood, the method invokes the AudioSrv!AudioServerStartStream function over LRPC:
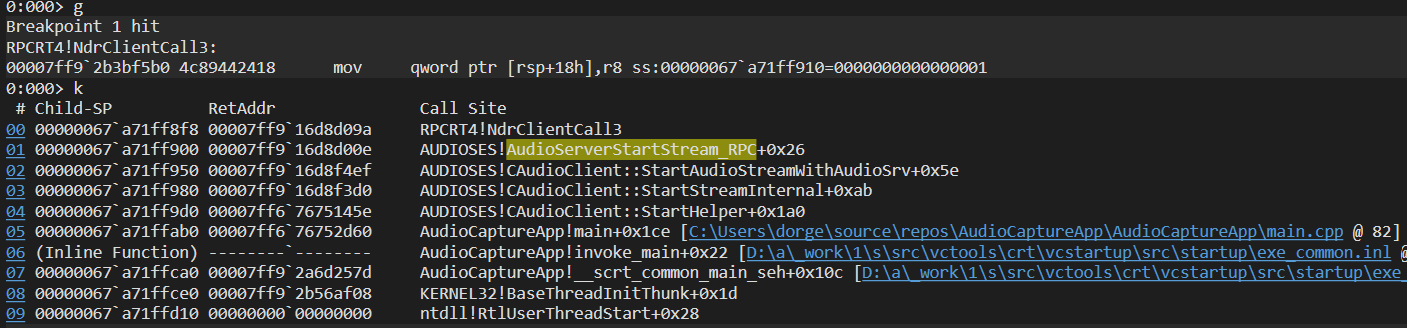
Dereferencing the MIDL_STUB_DESC structure passed to NdrClientCall3 we can extract the RPC interface UUID:
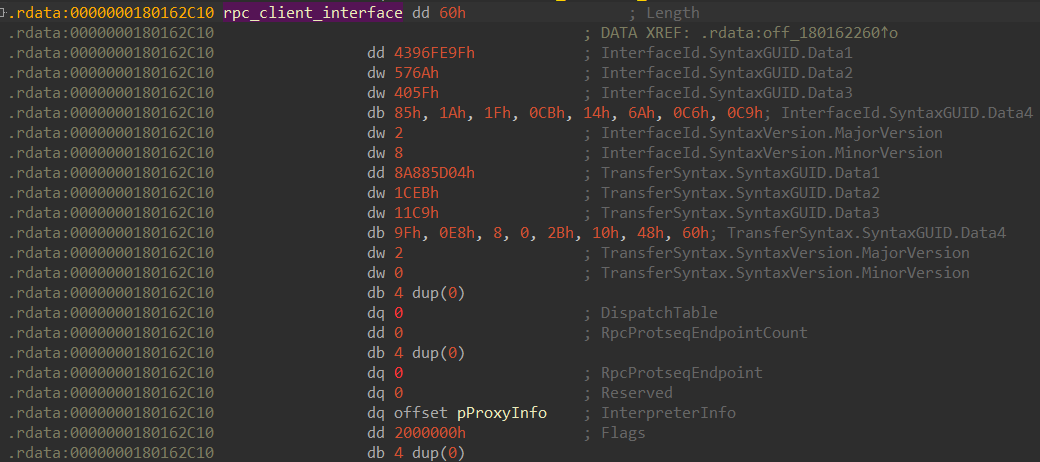
Using RPCView, we find out the RPC interface name is AudioClientRpc, Exported by AudioSrv.dll.
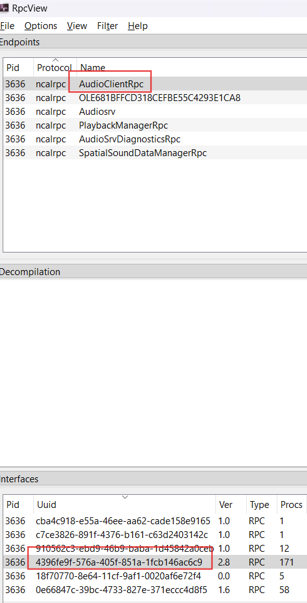
Specifically, as said before, procnum 8 is mapped to the AudioSrv!AudioServerStartStream.
Yes, in theory a runtime RPC hook can serve us here to maintain context about the recording process, but for obvious reasons monitoring from a process the attacker has already gained code execution in is not ideal, to say the least.
Let’s dig deeper. Statically reversing AudioSrv!AudioServerStartStream reveals a call to RtlPublishWnfStateData

For those unfamiliar with WNF, I highly recommend you check out Alex Ionescu’s black hat conference on the topic. In a nutshell, WNF is a notification system where processes can subscribe and publish events without the need for other processes to be there. In the snippet above, the audio service publishes an WNF_AUDC_CAPTURE event, indicating a process has started / stopped capturing audio. By attaching to the audio service, placing a breakpoint on ntdll!RtlPublishWnfStateData and running our audio recording sample we can confirm that is indeed the case.
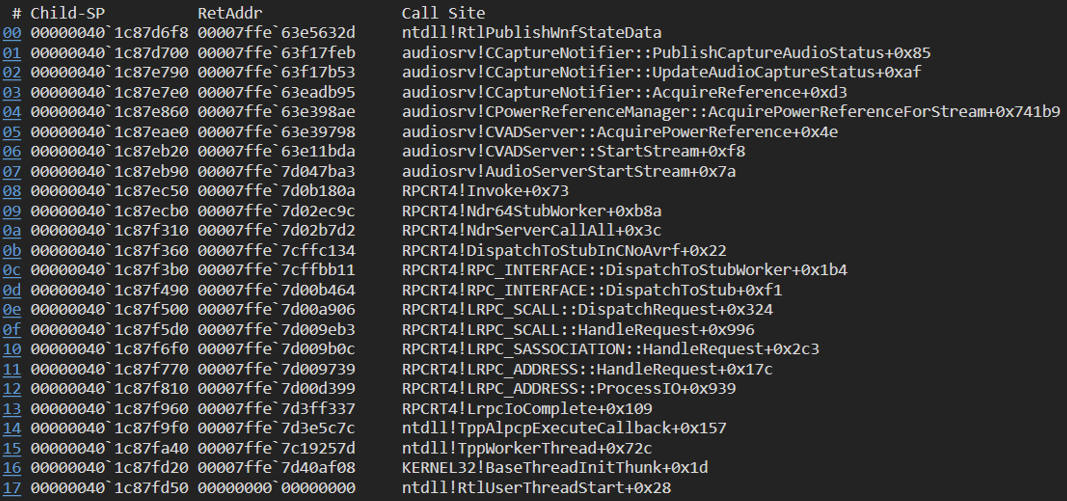
We can be called whenever a process is starting to capture audio, cool! but does WNF give us information about the recording process? let’s inspect the data passed by the publisher
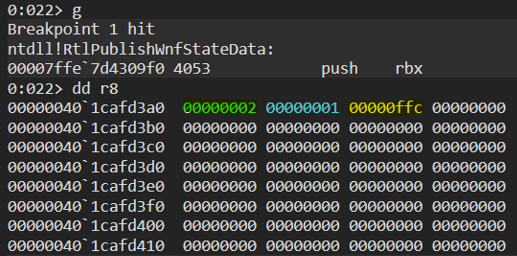
In the 4 bytes marked in blue we find the number of processes currently using the microphone, and in the bytes marked in yellow we find the process id of our audio recording process! WNF is undocumented, but thanks to previous reverse engineering work on the API, we can write the following callback:
NTSTATUS wnf::Callback(PWNF_SUBSCRIPTION Subscription, PWNF_STATE_NAME StateName, ULONG SubscribedEventSet, WNF_CHANGE_STAMP ChangeStamp, PWNF_TYPE_ID TypeId, PVOID CallbackContext)
{
NTSTATUS Status = STATUS_SUCCESS;
ULONG BufSize = 0;
PVOID pStateData = nullptr;
pAudioStateData AudioCaptureStateData = nullptr;
WNF_CHANGE_STAMP changeStamp = 0;
Status = ExQueryWnfStateData(Subscription, &changeStamp, NULL, &BufSize);
if (Status == STATUS_BUFFER_TOO_SMALL)
{
pStateData = ExAllocatePoolWithTag(NonPagedPool, BufSize, TAG);
if (!pStateData)
return STATUS_UNSUCCESSFUL;
Status = ExQueryWnfStateData(Subscription, &ChangeStamp, pStateData, &BufSize);
if (NT_SUCCESS(Status))
{
AudioCaptureStateData = reinterpret_cast<pAudioStateData>(pStateData);
for (int i = 0; i < AudioCaptureStateData->NumberOfEntries; i++)
{
DbgPrint("[*] AudioGuard :: Wnf :: process capturing audio -> 0x%x\n", AudioCaptureStateData->Entries[i]);
}
}
ExFreePoolWithTag(pStateData, TAG);
}
return Status;
}
Problem solved?
Sounds like it, doesn’t it? we can use WNF to get the PID of the recording process, and combine it with the filtering of IOCTL_KS_PROPERTY - KSSTATE_RUN IRPs to selectively block / allow microphone access on a per process basis… Well - not quite, nope. The audio service publishes a WNF event only upon the completion of the IOCTL_KS_PROPERTY - KSSTATE_RUN, which renders WNF unusable for our purpose. Having said that, the process id published by RtlPublishWnfStateData has to come from somewhere, hopfully we can access it from within the audio service before the IOCTL_KS_PROPERTY - KSSTATE_RUN IRP is initiated.
Finding where the PID is initialized
Whilst we can’t use WNF directly, it did have access to the recording process PID. Could be interesting to find where the PID is retreived.
RtlPublishWnfStateData is called from AudioSrv!AudioServerStartStream,so let’s start by inspecting it’s parameters
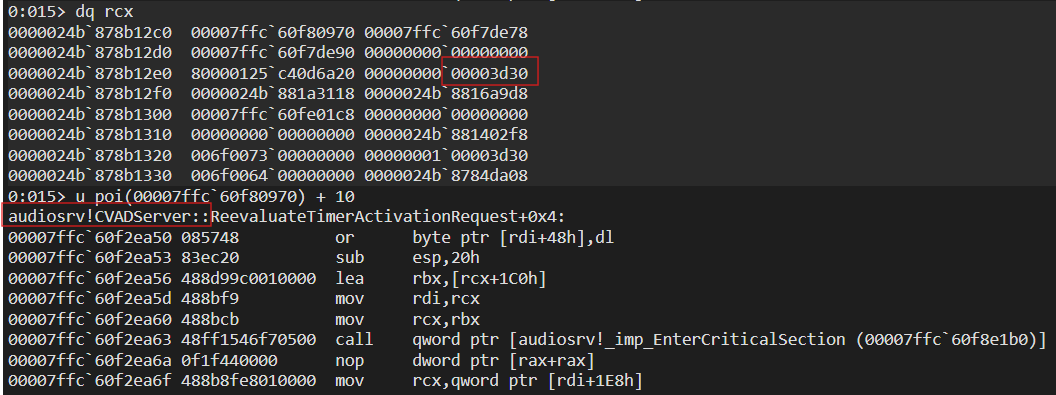
We can see the first argument is a pointer to an object of type audiosrv!CVADServer, one of it’s fields contains the PID of the audio recording process (0x3d30 in this case). the audiosrv!CVADServer object is initialized in audiosrv!AudioServerInitialize_Internal which is called in a response to the initial client call to pAudioClient->Initialize.
We need to identify where the PID is initialized to determine whether it can be trusted, I mean if the PID is provided by the client, it can’t be. Reversing of the function reveals audiosrv!AudioServerInitialize_Internal constructs an object of type IAudioProcess,and passes it to AudioSrvPolicyManager!CApplicationManager::RpcGetProcess :

CProcess is an object pointed by one of the fields of IAudioProcess
Reversing of AudioSrvPolicyManager!CApplicationManager::RpcGetProcess reveals the pid is retreived via RPCRT4!I_RpcBindingInqLocalClientPID, a method used by ncalrpc servers to identify the client process id from the server context.

LRPC requests are sent over ALPC, where each message delivered contains both the data and the ALPC protocol header, described by a
PORT_MESSAGEstructure. This header has aClientIdfield, which has both senders PID and TID. Upon receiving an ALPC request the RPC runtime inside the server process saves these values in theRPC_BINDING_HANDLEobject, where they can be retrieved from just like above
The retreived PID is then stored in the IAudioProcess object. Later on, the same IAudioProcess object is used to construct CVADServer, explaining how the first argument to AudioServerStartStream is initialized.

Now that we know the client pid is coming from the RPC runtime and is not directly controlled by client input, a runtime hook on AudioSrv!AudioServerStartStream is a valid option to identify the recording process! I will leave the task of extending the driver for the reader, as the way to configure the allow / block process configuration really depends on your environment, and is straightforward from a techniqual perspective.
Final notes
Many AV-like detection capabilities can be implemented through built in mechanisms such as ETW, callbacks, WFP and minifilters. With audio though, we had to develop our own heuristic, learning about kernel streaming and the way the audio subsystem’s components interact with each other in the process. As always, feel free to contact me on X for any questions, feedback, or otherwise, you may have! thanks for reading!